mutation predictions | marginal predictions | summary statistics | genome diff | command line log
|
breseq version 0.27.1 revision 87c22d663cc3
mutation predictions | marginal predictions | summary statistics | genome diff | command line log |
| read file | reads | bases | passed filters | average | longest | mapped | |
|---|---|---|---|---|---|---|---|
| errors | pgi-KO_S9_L001_R2_001 | 948,660 | 201,880,906 | 100.0% | 212.8 bases | 218 bases | 98.5% |
| errors | pgi-KO_S9_L001_R1_001 | 948,702 | 272,834,228 | 100.0% | 287.6 bases | 301 bases | 99.0% |
| total | 1,897,362 | 474,715,134 | 100.0% | 250.2 bases | 301 bases | 98.8% |
| seq id | length | fit mean | fit dispersion | % mapped reads | description | ||
|---|---|---|---|---|---|---|---|
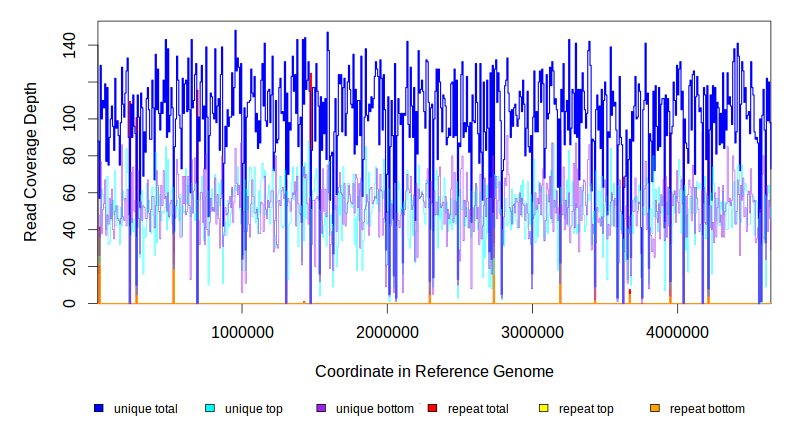
| coverage | distribution | NC_000913 | 4,641,652 | 108.7 | 3.1 | 100.0% | Escherichia coli str. K-12 substr. MG1655, complete genome. |
| total | 4,641,652 | 100.0% |
fit dispersion is the ratio of the variance to the mean for the negative binomial fit. It is =1 for Poisson and >1 for over-dispersed data.
| option | limit | actual |
|---|---|---|
| Number of alignment pairs examined for constructing junction candidates | ≤ 100000 | 1833 |
| Coverage evenness (position-hash) score of junction candidates | ≥ 2 | ≥ 2 |
| Test this many junction candidates (n). May be smaller if not enough passed the coverage evenness threshold | 100 ≤ n ≤ 5000 | 91 |
| Total length of all junction candidates (factor times the reference genome length) | ≤ 0.1 | 0.012 |
| reference sequence | pr(no read start) |
|---|---|
| NC_000913 | 0.87316 |
pr(no read start) is the probability that there will not be an aligned read whose first base matches a given position on a given strand.
| option | value |
|---|---|
| Coverage evenness (position-hash) score of predicted junctions must be | ≥ 3 |
| Skew score of predicted junction (−log10 probability of unusual coverage evenness) must be | ≤ 3 |
| Number of bases that at least one read must overlap each uniquely aligned side of a predicted junction | ≥ 1 |
| option | value |
|---|---|
| Mode | Consensus/Mixed Base |
| Ploidy | 1 (haploid) |
| Consensus mutation E-value cutoff | 10 |
| Consensus frequency cutoff | 0.8 |
| Consensus minimum coverage each strand | OFF |
| Polymorphism E-value cutoff | 10 |
| Polymorphism frequency cutoff | 0.2 |
| Polymorphism minimum coverage each strand | OFF |
| Polymorphism bias cutoff | OFF |
| Predict indel polymorphisms | YES |
| Skip indel polymorphisms in homopolymers runs of | OFF |
| Skip base substitutions when they create a homopolymer flanked on each side by | OFF |
| step | start | end | elapsed |
|---|---|---|---|
| Read and reference sequence file input | 23:30:10 17 Jun 2016 | 23:30:50 17 Jun 2016 | 40 seconds |
| Read alignment to reference genome | 23:30:50 17 Jun 2016 | 23:33:34 17 Jun 2016 | 2 minutes 44 seconds |
| Preprocessing alignments for candidate junction identification | 23:33:34 17 Jun 2016 | 23:34:25 17 Jun 2016 | 51 seconds |
| Preliminary analysis of coverage distribution | 23:34:25 17 Jun 2016 | 23:37:06 17 Jun 2016 | 2 minutes 41 seconds |
| Identifying junction candidates | 23:37:06 17 Jun 2016 | 23:37:06 17 Jun 2016 | 0 seconds |
| Re-alignment to junction candidates | 23:37:06 17 Jun 2016 | 23:37:30 17 Jun 2016 | 24 seconds |
| Resolving alignments with junction candidates | 23:37:30 17 Jun 2016 | 23:39:33 17 Jun 2016 | 2 minutes 3 seconds |
| Creating BAM files | 23:39:33 17 Jun 2016 | 23:41:10 17 Jun 2016 | 1 minute 37 seconds |
| Tabulating error counts | 23:41:10 17 Jun 2016 | 23:43:45 17 Jun 2016 | 2 minutes 35 seconds |
| Re-calibrating base error rates | 23:43:45 17 Jun 2016 | 23:43:46 17 Jun 2016 | 1 second |
| Examining read alignment evidence | 23:43:46 17 Jun 2016 | 00:02:28 18 Jun 2016 | 18 minutes 42 seconds |
| Polymorphism statistics | 00:02:28 18 Jun 2016 | 00:02:28 18 Jun 2016 | 0 seconds |
| Output | 00:02:28 18 Jun 2016 | 00:03:20 18 Jun 2016 | 52 seconds |
| Total | 33 minutes 10 seconds | ||
{kind=link}